How Our Hunting Agent Actually Works

.avif)
Somewhere right now, an attacker is sitting inside a corporate network. They’ve been there for weeks. They didn’t trip an alert - they logged in with stolen credentials, moved laterally using built-in admin tools, and blended in with normal traffic. Nobody is looking for them; not because the security team doesn’t care, but because they don’t have the time or tooling to hunt for something that hasn’t already set off an alarm.
This is the gap our hunting agent was built to close.
What Threat Hunting Means In Practice
Most organizations do one of two things and call it “threat hunting.”
The first is IOC matching: checking whether a known-bad indicator - a file hash, IP address, or domain - appears in your environment. This is useful, but fundamentally reactive. It only finds threats someone else has already discovered and published. Worse, by the time an indicator is published, it’s often already stale. The infrastructure it points to has been burned and abandoned by the attacker. IOC matching doesn’t just lag behind threats, it frequently searches for where the adversary used to be.
The second is hypothesis-driven hunting. It starts from an assume-breach mindset: instead of waiting for an alert, you assume an attacker is already inside and your detections missed them. Then you ask how they would behave. How would they maintain persistence? Move laterally? Escalate privileges? That leads to questions like: “Is an attacker persisting through malicious Windows services in our environment?” asked without relying on any known IOC.
This is what catches sophisticated threats designed to evade traditional detections.
The tools that exist mostly make that expert a little faster, a chat assistant to help write a query or summarize a result. None of them run the hunt end to end. The industry talks about hypothesis hunting constantly, yet almost nobody operationalizes it.
Automating It Is Only Half the Problem
So we built an agent to do hypothesis-driven hunting automatically - to hold the hypothesis, query the data, and narrow toward the truth without a person doing it by hand. That solves the resource problem: a hunt can run across hundreds of environments at once, instead of burning a scarce expert’s week on each one.
But automating it creates a second problem.
An LLM can hand you an answer that sounds completely reasonable and is still wrong. Point one at a pile of unusual logins and it will confidently conclude “these are probably just employees working late,” and move on, without ever checking whether that’s true. You’d just get that clean-looking report, with an attacker still sitting inside.
So we built the agent to a far higher standard: a plausible answer isn’t good enough. It can’t simply reason its way to a conclusion, it has a specific set of tools it must use to check every claim against the actual data, and it records every step it takes as it goes. If it can’t back a decision with evidence it pulled itself, it can’t act on it. And because the whole process is logged, our analysts can follow the agent’s reasoning from start to finish and see exactly why it did what it did.
Evidence over assumption, and a complete record of how it got there. The rest of this post is how we made that real.
Hunting Is a Conversation, Not a Query
This is the core of how the agent actually works.
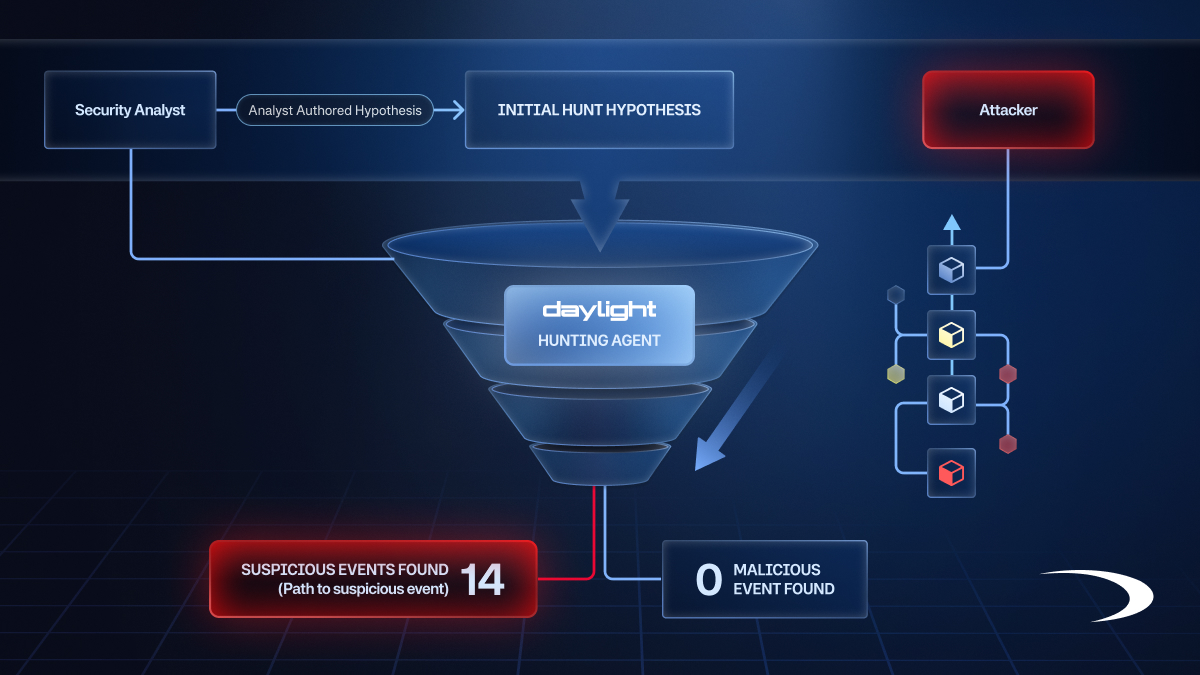
A hypothesis hunt isn’t a query that returns “found” or “not found.” It’s a funnel, and we mean that structurally, not as a figure of speech.
Every funnel starts with a specific hypothesis - a concrete piece of malicious activity you want to search for, like “an attacker persisting through malicious Windows services” or “compromised credentials being used for off-hours access.” The hypothesis is what gives the funnel its direction: it defines what the agent is looking for, and therefore what counts as “noise” versus what demands investigation.
Think of it this way: You start at the wide end with every event that could possibly be relevant - every service creation, every off-hours login, every cross-account role assumption in the last 90 days. Millions of rows. Somewhere in that haystack, there might be an attacker. Or there might not. You don’t know yet, and that uncertainty is the point.
The agent’s job is to systematically narrow that funnel, turning noise into signal. It explores the data, identifies what’s clearly benign, verifies that from the data itself, and removes it - layer by layer, until only the activity that can’t be explained remains.
When the hunt is done, an analyst can review every step of this process. The funnel isn’t just how the agent thinks, it’s how the analyst audits.
In practice, a hunt might start with millions of service creation events and, through successive rounds of verified filtering, reduce them to a handful of genuinely suspicious rows, one of which turns out to contain an encoded download cradle installed via compromised credentials. Broad to narrow, noise to signal, millions of rows down to the handful that can’t be explained.
Building the Right Instincts
One of the most challenging parts of building this agent was learning how to evaluate whether it was actually thinking like a hunter, or just producing output that looked like it was.
Early on, I sat down with our security analysts and asked them to walk me through exactly what they look at, step by step. They showed me what makes a filtering decision justified versus lazy, how to tell when reasoning matches the data versus when it just sounds plausible, and when something subtle deserves a second look.
That kind of knowledge gave me a framework for reading the agent’s output with real rigor. I could watch hunts run across different environments and know exactly what to look for: where the reasoning was sound, where it took shortcuts, where it got the right answer for the wrong reasons.
That’s what made the difference. Not changing the prompt every time something looked off, but building up enough pattern recognition across many hunts to know which gaps were systemic and which were one-offs. When I did make changes, they were precise, one rule addressing a failure mode I’d seen repeat across environments, not a reaction to a single bad output.
Verification Over Assumption
This is where we separate from “we threw an LLM at our SIEM.”
The agent follows a hard rule: a plausible narrative is not verification. If the agent suspects a benign explanation for a cluster of events, it must query the data to confirm, not just reason about it.
For example, if the agent sees users with Australian email addresses in an off-hours login dataset, it can’t simply reason “different timezone, off-hours logins are expected” and move on. It has to go to the data and confirm that explanation before applying any filter. If the evidence doesn’t support the narrative, the narrative gets discarded.
The same principle applies everywhere. If the data available covers 7 days, the agent cannot claim a 30-day historical analysis confirmed something is normal, that data wasn’t available. If a hypothesis describes a multi-part signal, explaining away one part doesn’t close the hunt. Every part must be independently verified.
Three Exits, Zero Ambiguity
The agent has exactly three ways to end a hunt. There is no “looks fine” option.
- Clean — Zero rows remain. Proven by a count query, not estimated.
- Cannot Filter Further — Rows remain that the agent genuinely cannot explain as benign after exhausting every angle. These are handed to a human analyst with full context.
- Confirmed Threat — Direct evidence of attacker-controlled activity. Immediate escalation.
The system enforces this with hard rules. The agent cannot say “nothing suspicious found” while rows still exist. It cannot say “can’t filter further” while simultaneously describing the remaining rows as normal - that description is itself a filter, so it must write the query. And it cannot confirm a threat based on suspicion alone, it needs direct evidence.
Compare this to tools that give you a confidence score or a “low/medium/high” severity. Our system gives you a deterministic outcome with a complete reasoning trail.
Every Step Is Auditable
We noted the agent records every step, here’s what that record actually contains. The audit trail isn’t a summary bolted on at the end. It’s the funnel itself. Everything is recorded: the queries the agent ran, the rows it saw, the distribution it explored, the filter it chose, the count that verified the filter worked. An analyst reviewing a completed hunt doesn’t see “the AI concluded X.” They see a chain of decisions: each one grounded in a specific query and a specific result, and they can challenge any link in that chain.
That’s the difference between “explainable AI” and an actual reasoning trail. The analyst can point at a specific step and say: “This filter was wrong. The agent removed rows it shouldn’t have.” And because every prior step is preserved by the threat-hunt orchestration we built, the agent can be re-run from that point with a correction. No work is lost. The analyst directs. The agent does the querying grunt work.
The AI doesn't replace the analyst. It gives them something they’ve never had: a structured investigation they can review, challenge, and redirect, instead of a blank query console and a pile of raw logs.
One Hypothesis, Every Customer
When we write a hunt, for example, “detect access key abuse in AWS” - it runs across our entire customer base. It doesn’t matter whether a customer’s logs sit in a data lake or a SIEM. The hunting methodology is the same. The agent adapts how it queries the data to match wherever the logs live, but the reasoning - what to filter, what’s suspicious, when to stop - doesn’t change.
A shared hunt definition is not a generic one. The hypothesis is universal, but what counts as “normal” is not, so the agent baselines every environment against its own data before it calls anything an anomaly. It doesn’t carry assumptions from one customer into the next; it establishes, from the environment in front of it, what’s expected there and what genuinely stands out. That per-environment grounding is what lets a single hunt run everywhere without burying each customer in false positives.
So a hypothesis we develop from one engagement is immediately actionable everywhere. We don’t rewrite the hunt per customer, and we don’t maintain separate playbooks per platform, yet every run is still baselined against the environment it’s hunting in. One hunt definition, executed across hundreds of environments, with the same rigor applied to each.
Threat hunting has never been limited by a lack of expertise, it’s been limited by the ability to apply that expertise consistently, at scale, and with rigor that doesn’t degrade under pressure. That’s what the agent solves, not a replacement for the analyst, but the thing that makes sure the work actually gets done, and done in a way they can stand behind.