How we do Detection Engineering at Daylight

.avif)
At Daylight we have positioned ourselves to be a Managed Agentic Security Service (MASS) provider, and that means we lean hard into “Agentic” in many processes. One of these process is a core part of our service offering as an MDR; Detecting suspicious activities in the client’s environment.
Our Detection Engineers are responsible for creating and maintaining Detections to ensure that we hit the right spot of signal-to-noise ratio, that is to optimize for catching real threats while minimizing false positives that create alert fatigue.
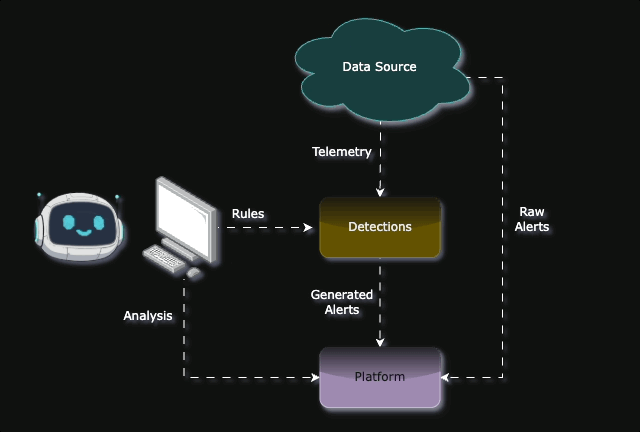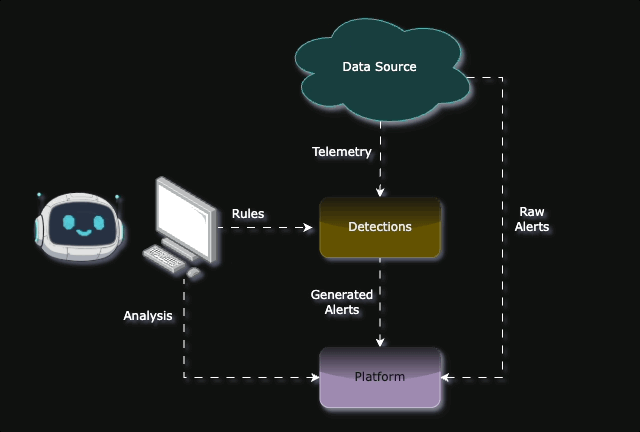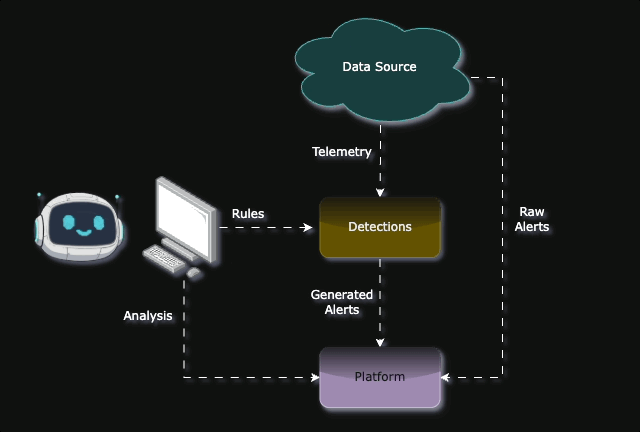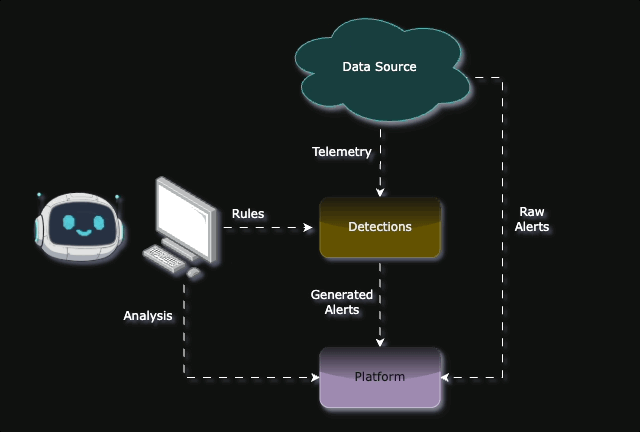
In this blog post, we will be laying out our approach to Detection Engineering and how we leverage AI to accelerate the process, while at the same time always having a human in the loop - putting the ”Managed” in MASS.
Detection-as-Code
Before we dive head first into the Lifecycle and AI augmented Engineering, its important for us to highlight how we treat our Detections as Code, and subsequently how AI accelerates our development around this paradigm.
In order to make our collection of Detections scalable and maintainable, we need to treat them like how we would treat code in Software Engineering. This means applying some of these industry-standard software development practices when building Detections:
- Version Control for repudiation, auditing, and recovery - every change is tracked, and we can roll back to previous versions if needed
- Comments and README files for description and explainability - ensuring that detections are self-documenting and future engineers can understand the intent
- CI/CD pipelines for unit testing, linting, secrets scanning, and automated deployment to different environments - catching issues early and deploying consistently
For these features, we’re using GitHub for our platform to host the code and pipelines.
As we walk through the Detection Engineering Lifecycle in the following sections, we'll dive deeper into how we incorporate these principles at each step of the way.
Detection Engineering Lifecycle
There are many definitions and frameworks for a Detection Engineering Lifecycle, but we have not formally adopted to any standard workflows. Instead, we do what’s best for us to operate at a cadence that we find acceptable, and produce quality results.
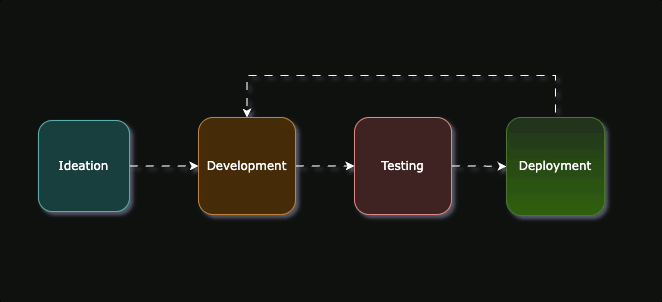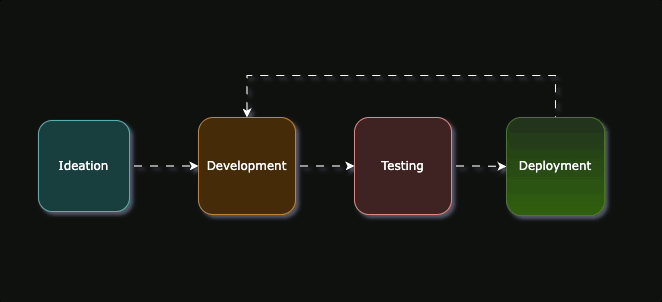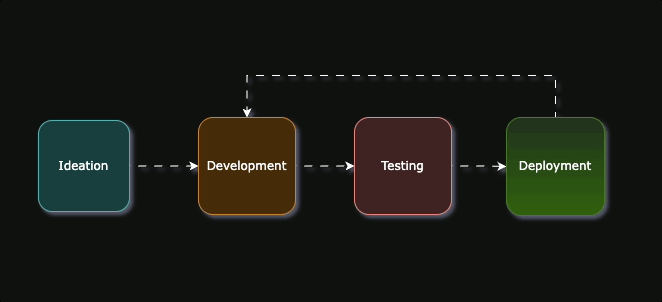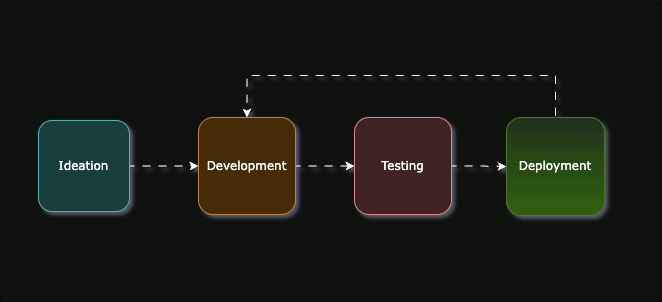
The flow is divided into 4 phases
- Ideation - the initial hypothesis
- Development - Writing the actual rules
- Testing - Testing the rule performance in different environments
- Deployment - Making the rule run on live data.
After Deployment, some rules need tweaking either because it’s too noisy, or it’s not capturing the intended behavior in production, so it goes back to Development and Testing again.
1. Ideation and Research
The Ideation stage is where every detection begins, and its here we gather ideas and information for new detections that are relevant from various sources:
- Threat intelligence reports and blog posts from the security community
- Customer requests based on their specific threat models, business context and tech stack
- Post-mortems on incidents that occurred in our customers environment, where we identify gaps in our existing detection coverage
Right at this initial ideation phase is where AI is enlisted. We execute our Agentic research process using a Claude command which performs web searching to gather various pieces of information such:
- Official documentation pages
- Security and Detection related articles
- Open source detection repositories such as Sigma or Elastic

The Agent doesn’t just gather all the resources into a single place, but also does some level of analysis to sort them and to provide descriptions as to what the link provides. After which, the Analyst will then review the summary of the findings and either gain inspiration, or be convinced that this detection idea would not work and move on to the next idea or request.
This is something that we trust the Agents to do, gathering information, as the task is fairly straightforward and menial. Without Agents, a human would do the same thing; search the web, click on relevant links, and summarize each site. However, this workflow does not discount the human element of discerning important information, which is what the Analyst does when reading the Agent generated summary.
2. Development
Being an AI-first company, engineers at Daylight have fully embraced AI assisted engineering to develop our Detections and pipelines. Its important to highlight that this paradigm is not the same as its chaotic counter-part; Vibe Coding. Instead we adopt Anthropic’s paradigm of defining skills that our agent should use (https://resources.anthropic.com/hubfs/The-Complete-Guide-to-Building-Skill-for-Claude.pdf) both in development and reviewing of the detection. This way the Agent has clear guidelines on the design patterns, available in-built functions and stylistic preferences when writing the detections, and this also ensures that it’s consistently enforced across all detections that are created.

When building Detections, we have two approaches
- Human-led - AI assisted
- AI-led - Human verified
In our experience, its the more complicated detections that need to be led by a Human, either because of optimization issues or edge cases that arise from the customers environment (certain users and service accounts should be ignored). This means that the design choices, constraints and AI assistance comes into play when we want to generate snippets of code that can be challenging to materialize within the Detection - e.g. a 7-day sliding window over 5 minute time buckets. Our Security Analysts are not expected to be experts in query generation and optimization, and is where we outsource the heavy lifting to the Agents.

On the other hand, its the simple and straightforward Detections can be generated very quickly using AI due to the low complexity. For example, creating an alert if the login comes from a blocklisted country. In this flow, the analyst will review the output and make any tweaks to the skills the Agent uses before executing the generation again.

Finally, to ensure that our Detections are well documented and explainable, we adopted a modified version of the Alerting Detection Strategy Framework by Palantir (https://github.com/palantir/alerting-detection-strategy-framework/blob/master/ADS-Framework.md). This document describes the core detection logic, blind spots, and potential false positives, and serves as an important reference if we want to understand the alerts that are being generated.
Documenting analyst reasoning and considerations in prose alongside the detection query itself makes detections easier for humans to read and review, while also acting as a layer of context-engineering for Agents. When we later use Agents to analyze our detection repository for gaps, that embedded context allows them to reason about the intent, rationale, and nuance behind each detection, producing higher-quality analysis.

3. Testing and Validation
For each detection that was generated either Human-led or AI-led, test cases must be created to ensure that the Detection truly serves its purpose while keeping an acceptable Signal-to-Noise ratio.

While AI can have a heavy hand in generating Detections, test cases, test data and simulations must be generated manually. This is because we cannot risk any sort of hallucination of events that will never exist, and the tests must closely match the customer’s environment. The worse case scenario is having the AI “over-fit” into the Detection logic and create test data that will never exist just to pass the test case.
We have several environments that serve as our test bed, including a staging environment that is connected to products that closely mirror the customers, Cloud environments in Azure/AWS and VMs to run simulations and generate telemetry. Real customer data is also pulled into the test cases to better reflect what we see in production.
Once the test data has been generated, the test can be run manually via make test, but it’s also configured to execute on a Pre-push hook. So even if the Analysts forgets to run the test before committing, it’s still executed when the code is pushed.
#!/bin/bash
echo "Running tests before push..."
# Run make test
make test
# Capture the exit code
TEST_EXIT_CODE=$?
# If tests failed, prevent the push
if [ $TEST_EXIT_CODE -ne 0 ]; then
echo "❌ Tests failed. Push aborted."
echo "Fix the tests or use 'git push --no-verify' to skip this hook."
exit 1
fi
echo "✅ Tests passed. Proceeding with push..."
exit 0
4. Deployment
When the code is pushed to production, there are two states it can take
- Silent Mode
- Published Mode
During the testing phase, Detections are validated against simulated or historical data. However, to truly stress test the logic, they must be run against live data where edge cases and real-world variability can still expose mistakes or generate excessive noise. This is where Silent Mode becomes essential.
Silent Mode is a state where the Detections are hitting on live data, but the alerts that are created are not published live. Instead, the created alerts are only monitored through DataDog where we can see how often it fires, and under what conditions. Part of the Analysts role is to constantly monitor these metrics and make continuous improvements to the Detection logic. Note that Published alerts are also sent to DataDog for visibility of all cases.

Silent Mode is represented by a single feature flag in our Detection code. We also have other feature flags such as isEnabled if we wish to disable the detection completely in the case where it’s generating too many alerts even in silent mode.
name: Login from Suspicious Location
status: silent
isEnabled: true
detectionLogic: ...
...
Once we've monitored the Detection's performance in Silent mode for a predetermined period and are satisfied with the results, we transition the status of the Detection to Published. This means:
- Detections are applied on live data
- Alerts are created for analysts to investigate and respond to
- Customers receive notifications based on their configured thresholds
- The detection contributes to our overall security posture
name: Login from Suspicious Location
status: published
isEnabled: true
detectionLogic: ...
...
And with this final step, it completes the Detection Engineering lifecycle where an Idea becomes a Detection that generates Alerts.
Conclusion
In this post we’ve covered how a lot of our Detection Engineering work is empowered by AI, but at the same time having a Human-in-the-Loop for important phases such as test case generation, research validation and Human-Led engineering. We have also shown how by adopting the Detection-as-Code paradigm, all our Detections are version controlled, tested, and programmable via feature flags.
As the threat landscape evolves and AI capabilities grow, we’ve adapted accordingly and shifted from “Prompt Engineering” to “Skills Engineering”, all to help empower our Analysts to create better detections in a quicker, but controlled and guided way, but the principle will remain the same: build systems you can reason about, document the intent behind every decision, and never let automation outpace your ability to understand what it's doing.